 Much is said about the definition of Big Data, but for the sake of this blog let me reiterate:
Much is said about the definition of Big Data, but for the sake of this blog let me reiterate:
Big Data = ∑ (Volume + Velocity + Variety + Veracity + Complexity)
This means that you don’t have to have all of the 4V + 1C characteristics in order to call it Big Data. Any combination of 4V + 1C results in Big Data. For example, you may have as little as one gigabyte of data, while the complexity and veracity of the data is high – this still qualifies as Big Data.
The interesting part of Big Data is that an enterprise doesn’t know whether it needs this data or not until the analysis is done. Every enterprise has to consider and adopt new classes of technology to store, process, explore, discover, and analyze its Big Data. Typical value chains of Big Data are data origins/ producers, classified data sources, data storage, analytics, and consumers.
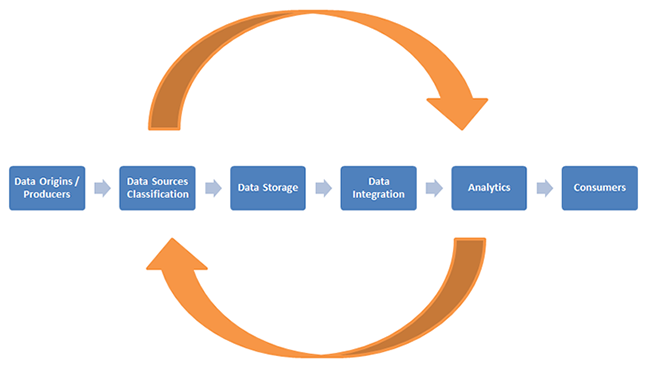
The feedback loop and cycle are from data source classification to analytics:
- Data Origins/ Producers: The Internet, sensors, machines, and so on
- Data Sources: Web log, sensor data, images/audio and videos, etc.
- Data Storage: Technologies supporting data storage, like RDBMS, NoSQL, distributed file system, and in-memory
- Analytics: Business analytics functions, system supporting business analytics, and predictive analytics are the major intent of Big Data analysis. Predictive analytics helps to find patterns in data to help decision makers or business processes.
- Consumers: Business processes, humans, and applications.
Three Key Fundamental Use Cases
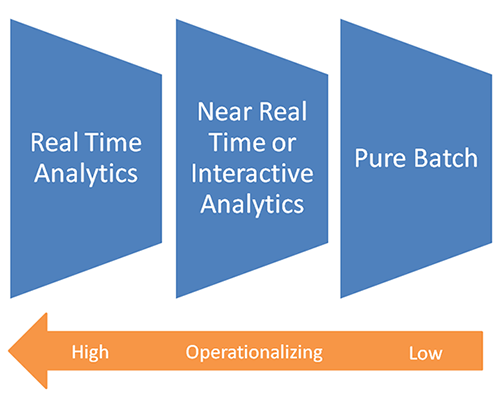
One of the most difficult use cases to handle is real-time analytics. Let’s put it this way – if you’re able to handle real-time analytics, your infrastructure, practices, and tools certainly can handle near real time and batch. Remember, real time has its context. Most real-time contexts are with their framework reference. For example, risk officers may want to make the daily decision to reshuffle their portfolios at 8.00 a.m. A real-time analysis to them, from the business use perspective, means an analysis done on the previous day’s data, because all they need are the numbers for today.
Similarly, each business situation is unique, so the real time context is unique for each business. In several business cases such as fraud detection, real time means instantaneous from data acquisition to decision.
In-Memory Platform Is Core of Real-Time of Analytics
Real-time analytics use cases go hand in hand with an in-memory platform. If you’re involved in a data science project, you know analytics is an iterative process that requires collaboration with stakeholders on an analytic life cycle. For many use cases, the number of iterations plays a huge role in model lift. In certain use cases, the analytical model is used only once—that is, it’s then thrown away.
Because of the very nature of the analytical process and its life cycle, you need a faster and most flexible environment where you’re able to assemble your analytical data set. One of the biggest promises that an in-memory system makes is for more speed and an agile environment with which to build your analytical data sets for analysis.
So the two key takeaways are:
- Whether you have a Big Data problem or initiatives, in-memory is an important block of your Big Data architecture
- Whether you do real-time analytics, near real-time analytics (interactive), or pure batch, you need an in-memory platform in your analytical process.
I am very interested in learning about your analytical use case pattern, how it fits into the three mentioned above, and how you see in-memory platform needs from your case perspective.
Read more: